Recupero dati da nastri magnetici del computer polacco MERA-400
All’incirca nel maggio 2015 Andrea “Mancausoft” Milazzo ci ha messi in contatto con Jakub Filipowicz, che in Polonia si occupa di ricerche storiche sul computer polacco MERA-400; Jakub sta scrivendo un emulatore per questo computer, di cui manca il sistema operativo, praticamente introvabile. (Maggiori dettagli sul sito mera400.pl)
Jakub e’ riuscito a trovare, presso il Museo di Tecnologia di Varsavia, 5 nastri magnetici contenenti copie del sistema operativo CROOK. Il museo non e’ in grado di leggerli. Dopo qualche mese e’ riuscito a farseli consegnare per tentare un recupero dati ed estrarre, almeno da uno di essi, l’introvabile sistema operativo.
Ci siamo offerti di collaborare da subito in questa impresa, cosi’ ci siamo fatti spedire i nastri, che abbiamo ricevuto tramite corriere, insieme ad un simpatico messaggio di “buona fortuna” che oggi e’ appeso nella nostra biblioteca 🙂

I nastri sono stati utilizzati attorno al 1990; sono stati ben conservati, nelle loro scatole originali, a temperatura costante e sigillati. Sembrano essere scritti in Phase Encoding a 1600 bpi, anche se probabilmente il primo blocco (header) del nastro e’ a 800bpi in standard NRZ, il che potrebbe creare qualche problema ai nostri sistemi di lettura, che leggono solamente 1600 / 3250bpi.
Il nostro Museo dispone di circa 3000 nastri magnetici di varie marche e tipologie; questo ci permette di trovare nastri dello stesso tipo di quelli oggetti di studio e dello stesso periodo storico, sui quali effettuare tutti i test necessari senza effettuare tentativi sui nastri originali, che potrebbero inutilmente danneggiarsi. I test riguardano la consistenza e lo stato del supporto magnetico e le eventuali tecniche necessarie alla sua stabilizzazione per una lettura dei dati (acclimatamento termico, trattamenti chimici, termici e meccanici).

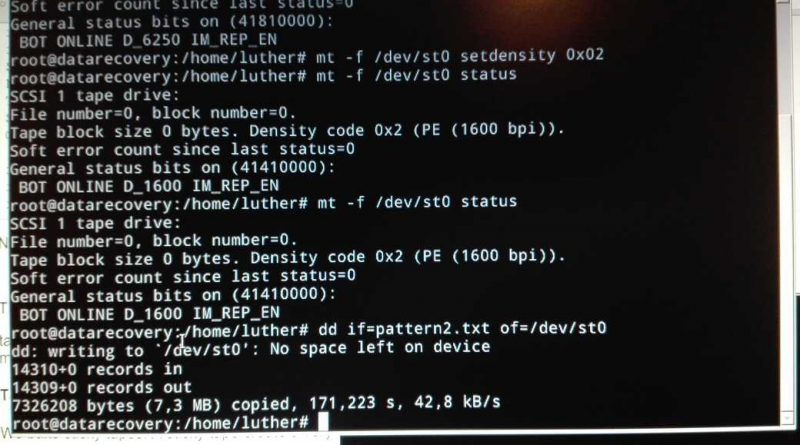
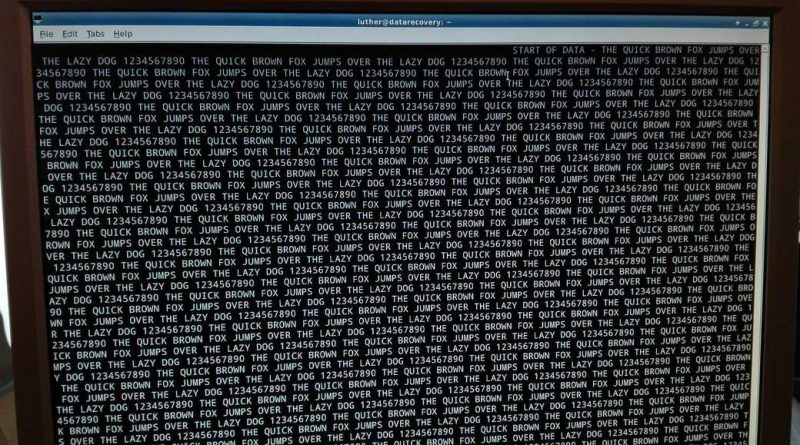
Inoltre, abbiamo proceduto a registrare su questi nastri, precedentemente dumpati e svuotati, con dei pattern di dati per tentarne la lettura. Fatto cio’, abbiamo proceduto al tentativo di lettura tramite il nostro sistema.
I sospetti di Jakub sull’impossibilita’ di leggere i nastri direttamente col nostro lettore (un IBM 9348) si sono rivelati fondati: l’header a 800bpi NRZ non viene riconosciuto dal lettore, e la lettura non puo’ neanche iniziare.
Si pone cosi’ il problema di recuperare un secondo lettore di nastri per effettuare il recupero dati. Nel nostro magazzino giace un tape reader Qualstar 1052, purtroppo privo della sua interfaccia di collegamento al computer (interfaccia di tipo PERTEC). Decidiamo comunque di prenderlo e di dare un’occhiata: l’idea e’ quella di costruire un hardware capace di leggere i dati cosi’ come escono dalla testina, e tradurli in bit.
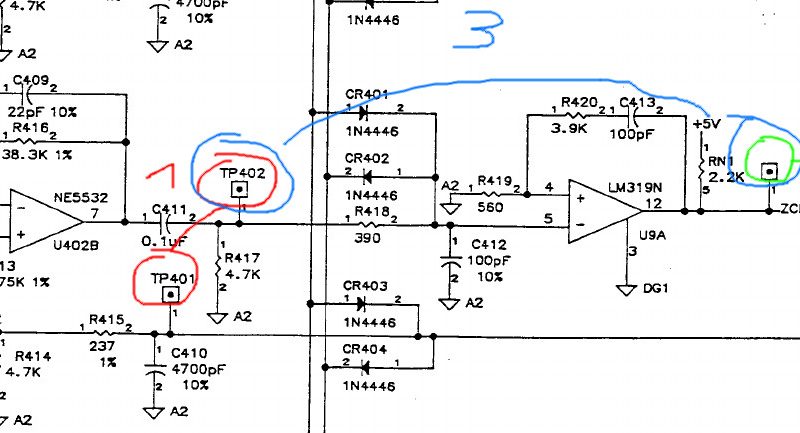
Aperto il drive, ci troviamo di fronte una scheda logica davvero ben progettata, nella quale spicca una suddivisione delle sezioni del circuito che ricorda le 9 tracce presenti su un nastro magnetico (8 bit + uno di parita’).

L’idea prende corpo: leggere i segnali non tanto dall’uscita della testina di lettura, ma gia’ nel circuto laddove questi segnali vengono trasformati in bit.
I primi test di questo sistema, utilizzando i nostri nastri di prova, vengono effettuati con un Arduino Mega, collegato alla circuiteria del tape, in appositi punti del circuito ricavati analizzando lo schema elettrico del drive, fortunatamente disponibile online. L’aiuto di Enzo “Katolaz” Nicosia, venuto a trovarci appositamente da Londra e, da remoto, di Mancausoft, da Cracovia, e’ stato fondamentale per effettuare questi test 🙂

Mettendo il drive in modalita’ TEST, riusciamo a far scorrere il nastro in maniera lineare dall’inizio alla fine, avanti e indietro; durante questo scorrimento, i dati vengono comunque interpretati dalla circuiteria del tape drive, e quindi possono essere letti dal nostro Arduino Mega.

Una discussione relativa a questo metodo si e’ sviluppata sul Forum della Vintage Computer Federation, ed e’ disponibile qui. Ringraziamo Al Kossow, Chuck Guzis, Gerardcjat e gli altri amici del VCF Forum che ci hanno aiutato! 🙂
Questo sistema ci porta ad una lettura lineare del nastro, tranne dell’header; inoltre, abbiamo qualche errore di lettura che purtroppo non riusciamo a risolvere, dato che il software dell’Arduino Mega non effettua alcun controllo sulla consistenza dei dati. Il risultato e’ comunque incoraggiante!
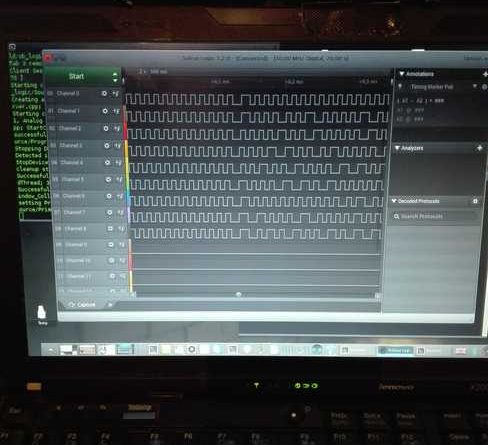
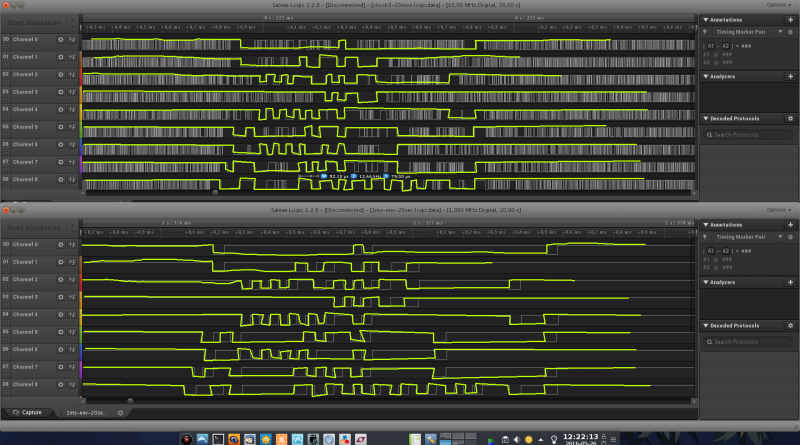
A questo punto Jakub propone di procedere diversamente: utilizzare, al posto dell’Arduino Mega, un analizzatore logico (Saleae) a 16 canali, procedere al dump dei segnali dell’intero nastro, ed interpretarli successivamente via software, secondo gli standard definiti su questo documento.
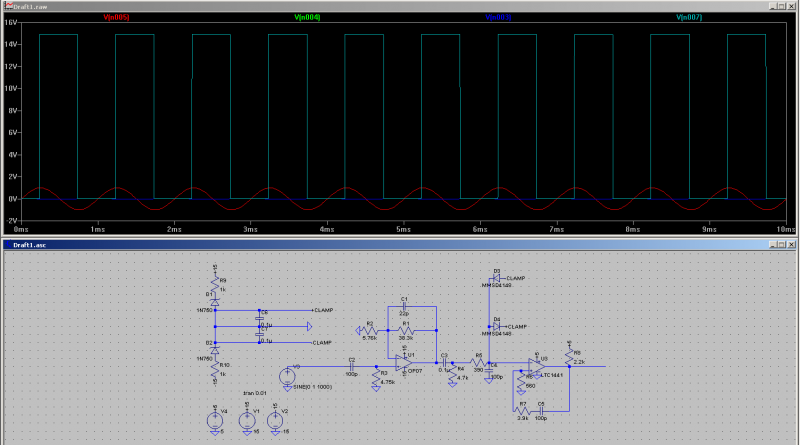
Ordiniamo un analizzatore logico cinese “Saleae” a 16 canali, ma nel frattempo Jakub ci spedisce il suo, con il quale possiamo iniziare i vari test di lettura sui nostri nastri di prova. Durante l’attesa dell’analizzatore, Jakub effettua dei test simulando la circuiteria del tape drive utilizzando LTSpice.
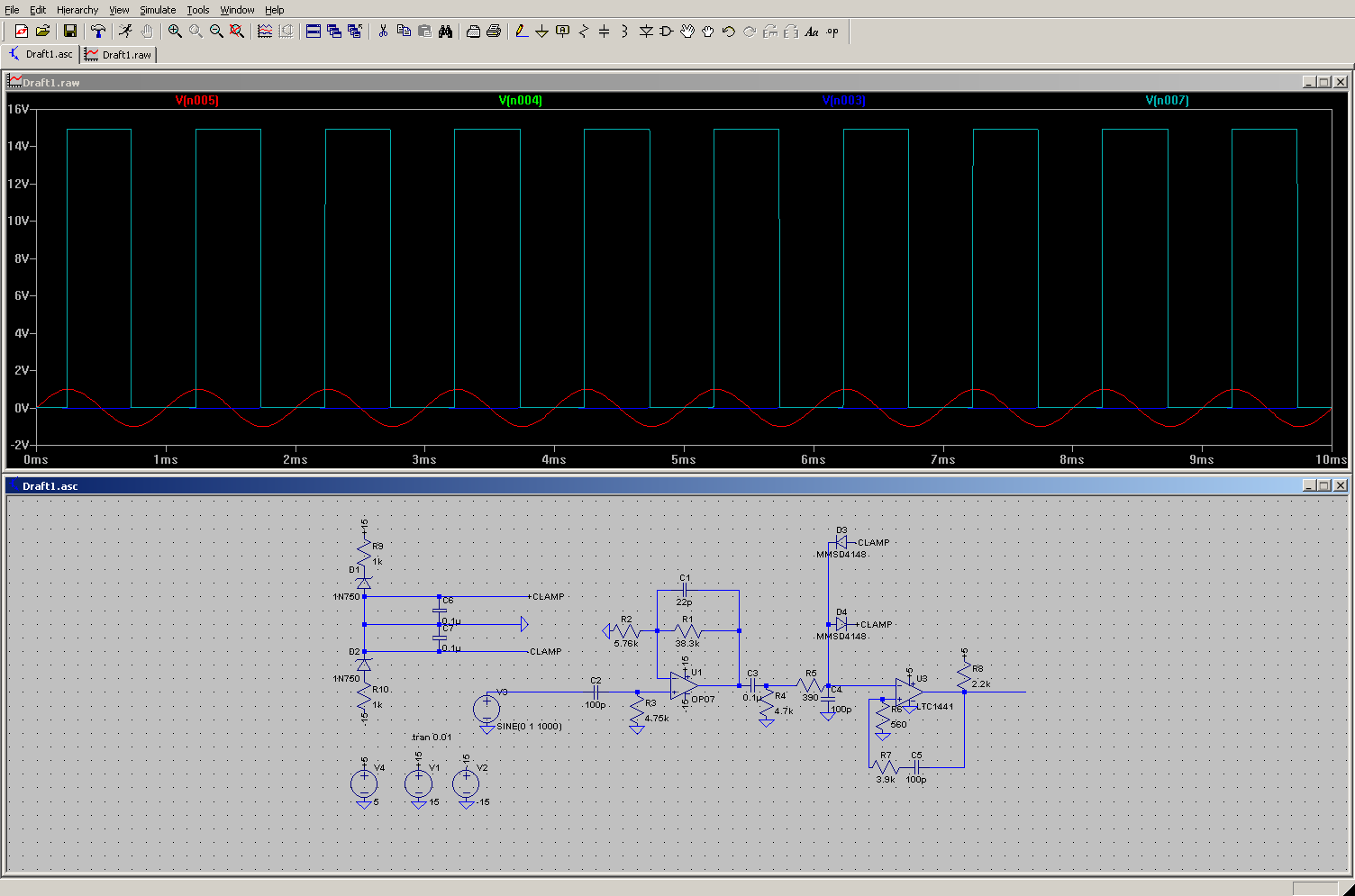
Il software si deve occupare di controllare la consistenza dei dati, risolvere il problema del disallineamento delle tracce tra loro (dovuto ai problemi intrinseci di costruzione di ogni testina magnetica) e di verificare la correttezza del dato tramite il bit di parita’, eventualmente correggendo gli errori di lettura.
Citando Jakub:
“The real problem I see is the processing power needed to do that sampling _reliably_. 1600BPI = 3200 flux changes per inch. At 20in/s (slowest drive speed I know of) it means 64kHz signal. Taking Nyquist frequency into account we need to sample at 128kS/s, but from my experience with such a type of signals (where clocking “floats” due to physical nature of media and drive) we need at least 5x-10x more than the signal frequency, so at least 320kS/s. Now, I don’t know how fast the Qualstar drive goes, but fastest speed for 1600BPI is 200in/s, which requires 3.2MS/s… And even 320kS/s can be a problem for an arduino – with 8MHz CPU you have ~25 instructions per sample to spend, in which you need to not only sample the data, store it in a buffer, do some maintenance work, but also send it to a host (not enough memory to store it locally). I really think that fast programmable logic analyzer is the way to go here. The key is to sample the data with precise intervals, otherwise later analysis becomes impossible.”
Uno dei tanti problemi e’ eliminare il “rumore”, una serie di piccoli glitch e variazioni di flusso magnetico che possono essere interpretati erroneamente come dati.
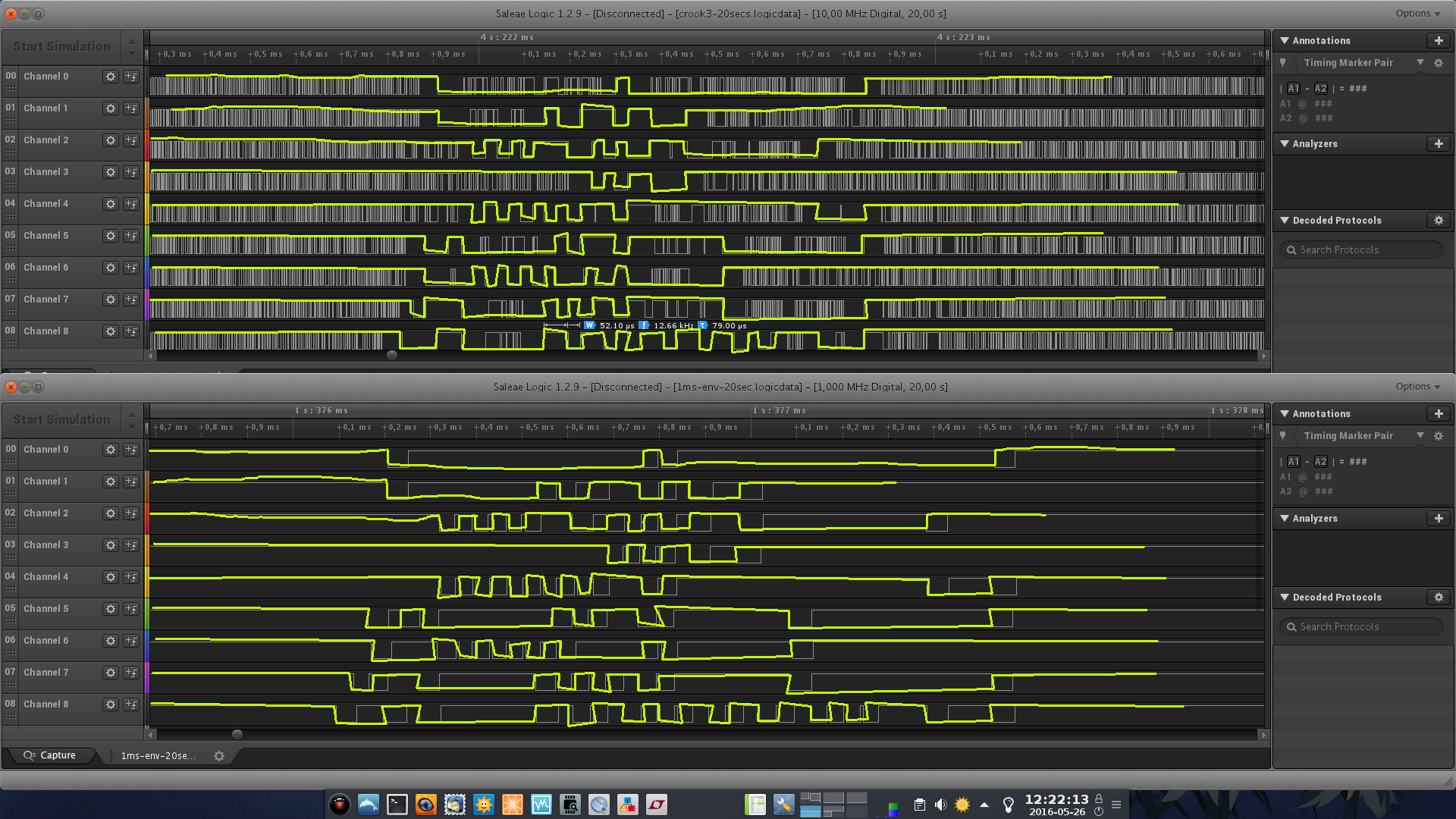
Il software viene sviluppato da Jakub Filipowicz con svariati test di lettura e debugging; e’ un bellissimo lavoro scritto in Python ed e’ disponibile su questo link.
Il bello di questo software e’ che e’ capace di leggere nastri magnetici registrati a qualsiasi BPI, quindi possiamo leggere sia l’header a 800 nonche’ tutti i dati successivi a 1600bpi, indipendentemente dalla velocita’ di lettura del nastro stesso.
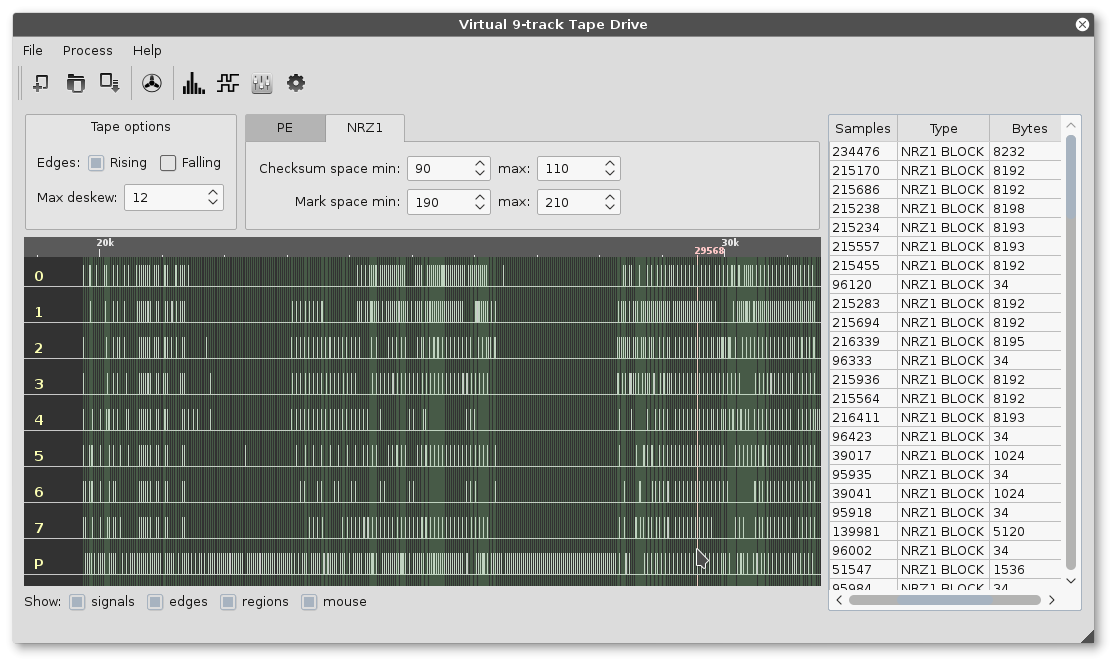
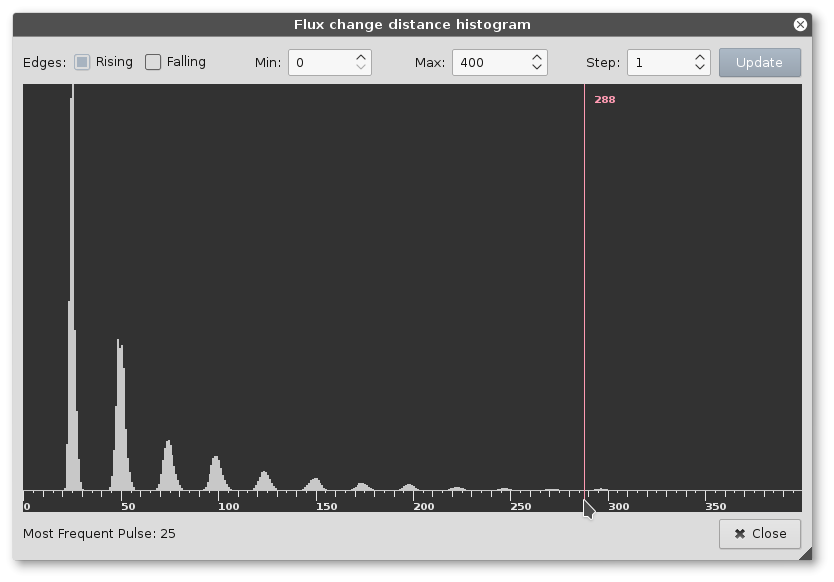
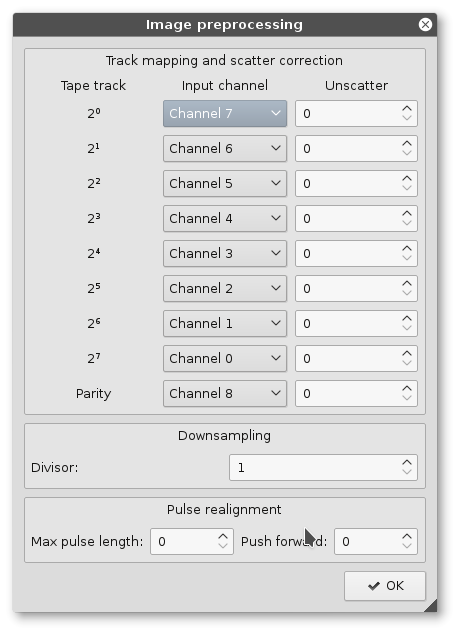
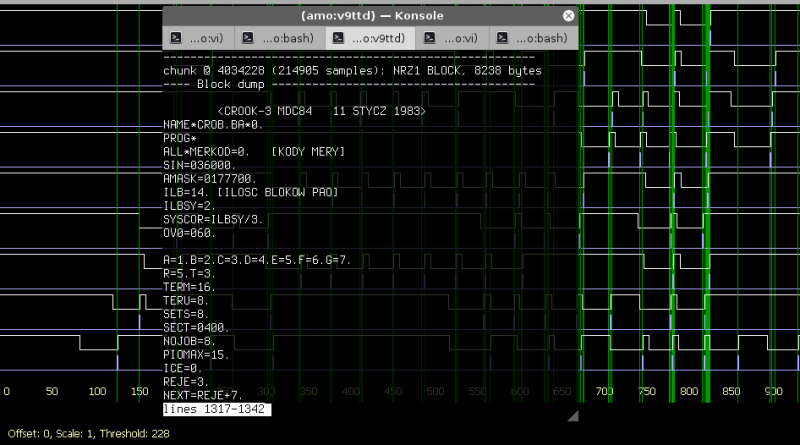
Regolare ogni parametro di funzionamento del software per estrarre i dati non e’ stato facile, ma alla fine siamo riusciti a leggere correttamente tutti e 5 i nastri magnetici senza alcun errore!
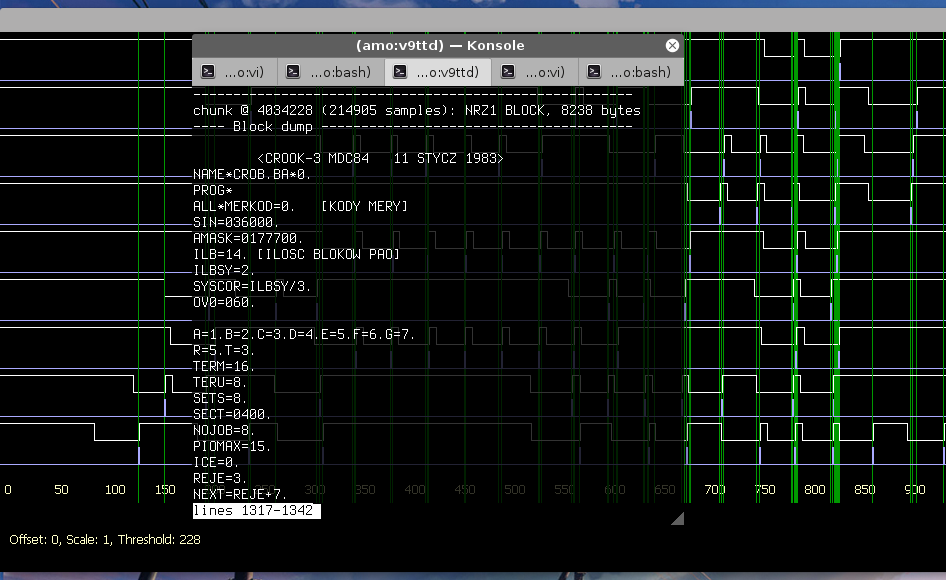
Abbiamo avuto cosi’ delle grandi sorprese: non solo abbiamo trovato una copia del sistema operativo CROOK, ma ne abbiamo trovate diverse versioni (CROOK 3, CROOK 4, CROOK 5), una immagine completa di un disco di sistema installato e funzionante, pronto per essere utilizzato con l’emulatore del MERA-400, nonche’ addirittura il codice sorgente dell’intero sistema operativo, piu’ diversi programmi applicativi.
In particolare, citando Jakub:
– SOM (MERA-400)
Huge numer of versions allow for reconstruction of the whole CROOK development process.
Other sources (hundreds of files) include various OS tools and utilities as well as:
* K-202 command shell
* CEMMA analog circuit simulator (several versions)
* 8080 simulator
* ASSK assembler (for MERA-400 and K202, dozens of versions)
* Basic (for K-202 and MERA-400)
And finally, the fifth tape contain several backups of a live MERA-400 system with complete CROOK-3 OS installed. This means we have a binary CROOK-3 “distribution” ready to run in the MERA-400 emulator. There are also users’ home directories with loads of other software in various stages of development.”
Per concludere, ecco il comunicato stampa finale sul lavoro effettuato, scritto da Jakub Filipowicz:
“Recent cooperation between Museo dell’Informatica Funzionante and mera400.pl, a Polish site specializing in preserving history of MERA-400 minicomputer familly, proved to be a great success.
We’ve managed to restore data from 5 NRZ1-encoded 9-track tapes written between early 70’s and early 80’s, despite the fact that we didn’t have an NRZ1 compatibile tape drive at our disposal.
Restoration was done in two phases. First, a low-level tape images were taken by tapping into 9 head signal paths with a logic analyzer, running all five tapes at a low speed of 50 in/s, and sampling the signals at a rate of 1MS/s. This eventually resulted in 2.2GB of raw head signal images ready for further processing.
To convert the signal data into actual files that were stored on a magnetic tape, custom software was needed. Second phase of the restoration process brought to life a software called “Nine Track Lab” – graphical tool that allows not only decoding NRZ1-encoded data, but also fixing problems related to tape age or drive’s read inaccuracies.
Development version of the software is available at: https://github.com/jakubfi/
Final result was a 100% success: 8340 data blocks were correctly read, yielding almost 1500 files written between 1973 and 1984. Among them were 260 files with source code of various K-202 and MERA-400 operating systems that were presumed lost until now: SOK-1, SOWA, CROOK-1, CROOK-2, CROOK-3 and CROOK-4. Other files contain sources of many utilities, as well as binary copies of a CROOK-3 installation taken from a running machine.
This collaboration made it possible to preserve for future generations an important part of Polish IT history. We are not only happy, but also proud that we could be a part of this process.”
Un articolo relativo a questo recupero e’ stato pubblicato sulla pagina Facebook del MERA-400.
Questo progetto non sarebbe stato possibile senza cio’ che, a nostro avviso, e’ la vera identita’ e caratteristica di un Museo: la collaborazione tecnica e scientifica tra ricercatori sparsi per l’Europa (Londra, Cracovia, Varsavia, Cosenza), nonche’ tra strutture ed entita’ diverse (noi, il MIAI di Cosenza, Dyne.org in Amsterdam, il Museo di Tecnologia di Varsavia). Il nostro grazie va a tutti i membri dello staff MusIF / MIAI / Dyne.org ed a tutti i soggetti coinvolti 🙂
Per ulteriori dettagli sul sistema MERA-400, il suo emulatore, software, informazioni tecniche ed altro ancora, vi rimandiamo al relativo sito internet.
Galleria immagini: